

How To Loop Through Dataframe And Change Values Python
Python
Yous Don't Always Have to Loop Through Rows in Pandas!
A look at alternatives to "for loops" with vectorized solutions.

I've been using Pandas for a while now, simply I haven't always used it correctly. My intuitive approach to perform calculations or edit my information tends to kickoff with this question:
How can I loop through (iterate) over my DataFrame to do INSERT_ANY_TASK_HERE?
Iterating over rows in a DataFrame may piece of work. In fact, I wrote a whole piece on how to edit your data in Pandas row by row.
The reason I did this is because I had a multi-layered calculation that for the life of me I couldn't figure out how to solve without looping. I had multiple weather, one of which involved taking a column value that had the proper noun of another column in the DataFrame which was to be used in a adding.
Iterating over the DataFrame was the just manner I could call up of to resolve this problem. Merely it shouldn't be the method yous always go to when working with Pandas.
In fact, Pandas fifty-fifty has a large ruby alert on how y'all shouldn't need to iterate over a DataFrame.
Iterating through pandas objects is by and large slow. In many cases, iterating manually over the rows is non needed and can exist avoided (using) a vectorized solution: many operations can be performed using built-in methods or NumPy functions, (boolean) indexing.
About of the time, you tin utilise a vectorized solution to perform your Pandas operations. Instead of using a "for loop" blazon operation that involves iterating through a gear up of data one value at a time, vectorization means you implement a solution that operates on a whole gear up of values at once. In Pandas, this ways that instead of computing something row past row, you perform the performance on the entire DataFrame.
The focus here isn't only on how fast the code can run with not-loop solutions, but on creating readable code that leverages Pandas to the total extent.
At present, let's go through a couple examples to help reframe the initial thought process from "how do I loop through a DataFrame?" to the real question of "how do I perform this calculation with the tools from Pandas?".
The information nosotros're going to use comes from an Animate being Crossing user review data gear up from Kaggle. We'll import the data and create two DataFrames, one called "former" and one chosen "new". And so, to get started on the basics of alternative solutions to for loops, we'll perform some operations with both a for loop and a vectorized solution and compare the code. (To empathise the logic behind the for loop codes below, please check out my previous piece on it, equally it already has an in-depth explanation on the subject field.)
import pandas equally pd old = pd.read_csv('user_reviews.csv')
new = pd.read_csv('user_reviews.csv')
An introduction to vectorized solutions in Pandas
Implementing "if-so-else"
Let's create a new column called "qualitative_rating". This fashion, nosotros tin can create some broad categories to label each user review equally "bad", "ok", and "skilful". A "bad" review will be whatever with a "grade" less than 5. A expert review will exist whatever with a "grade" greater than five. Any review with a "form" equal to v will be "ok".
To implement this using a for loop, the code would await like this:
# if then elif else (one-time) # create new column
one-time['qualitative_rating'] = '' # assign 'qualitative_rating' based on 'grade' with loop
for index in former.index:
if one-time.loc[index, 'course'] < 5:
old.loc[index, 'qualitative_rating'] = 'bad'
elif old.loc[index, 'form'] == 5:
old.loc[index, 'qualitative_rating'] = 'ok'
elif old.loc[index, 'class'] > five:
old.loc[alphabetize, 'qualitative_rating'] = 'proficient'

The lawmaking is easy to read, but it took seven lines and two.26 seconds to get through 3000 rows.
Instead, a better solution would look like this:
# if so elif else (new) # create new column
new['qualitative_rating'] = '' # assign 'qualitative_rating' based on 'grade' with .loc
new.loc[new.class < v, 'qualitative_rating'] = 'bad'
new.loc[new.grade == 5, 'qualitative_rating'] = 'ok'
new.loc[new.course > v, 'qualitative_rating'] = 'skillful'
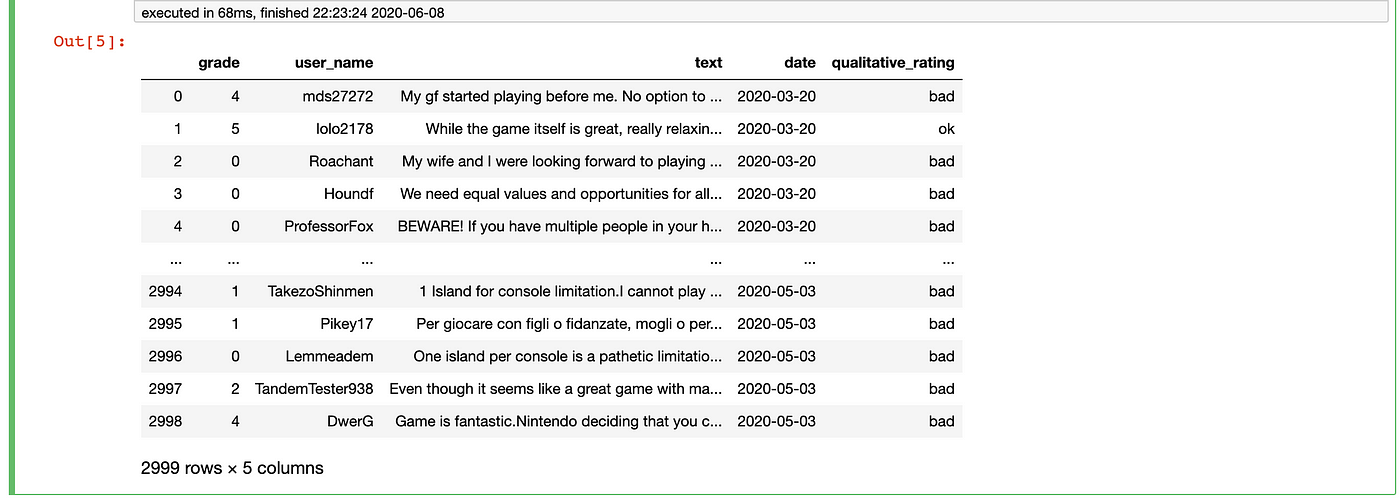
This time, the lawmaking to add the qualitative ratings was only composed of three lines, and information technology just took 68 milliseconds. I as well used the ".loc" DataFrame function again, only this time, I used it "properly". By that, I hateful instead of using a looped "if-else" solution, I assigned the "bad", "ok", and "adept" qualitative rating direct from the ".loc" pick.
Counting length of column value
Our next new column "len_text" will evidence the number of characters in each review, so we can compare the length of different reviews in the information set.
To implement this using a for loop, the code would look like this:
# create column based on other cavalcade (old) # create new column
old['len_text'] = '' # calculate length of cavalcade value with loop
for index in old.index:
one-time.loc[index, 'len_text'] = len(old.loc[index, 'text'])
Again, ii lines and 2.23 seconds for this calculation is not that long. But instead of going through each row to notice the length, we could use a solution that simply requires one line:
# create cavalcade based on other cavalcade (new) # create new column
new['len_text'] = '' # summate length of column value by converting to str
new['len_text'] = new['text'].str.len()
Hither, we take an existing column's values, plough them into strings, then use ".len()" to get the number of characters in each string. This solution only took 40 milliseconds to run.
Creating a new column based on multiple weather and existing cavalcade values
Now let's create a new column chosen "super_category". Hither, we'll identify if people authorize as a "super reviewer", or in this instance, if the length of their review is greater than 1000 characters. We'll also mark a super reviewer as a "super fan" if the review "form" is greater than or equal to 9, and a "super hater" if the review "course" is less than or equal to i. Everyone else will be categorized as "normal".
Implementing this with a for loop would look similar this:
# new column based on multiple conditions (one-time) # create new column
old['super_category'] = '' # ready multiple conditions and assign reviewer category with loop
for alphabetize in old.alphabetize:
if old.loc[alphabetize, 'class'] >= ix and onetime.loc[index, 'len_text'] >= grand:
old.loc[index, 'super_category'] = 'super fan'
elif one-time.loc[alphabetize, 'grade'] <= 1 and old.loc[index, 'len_text'] >= 1000:
one-time.loc[index, 'super_category'] = 'super hater'
else:
old.loc[index, 'super_category'] = 'normal'
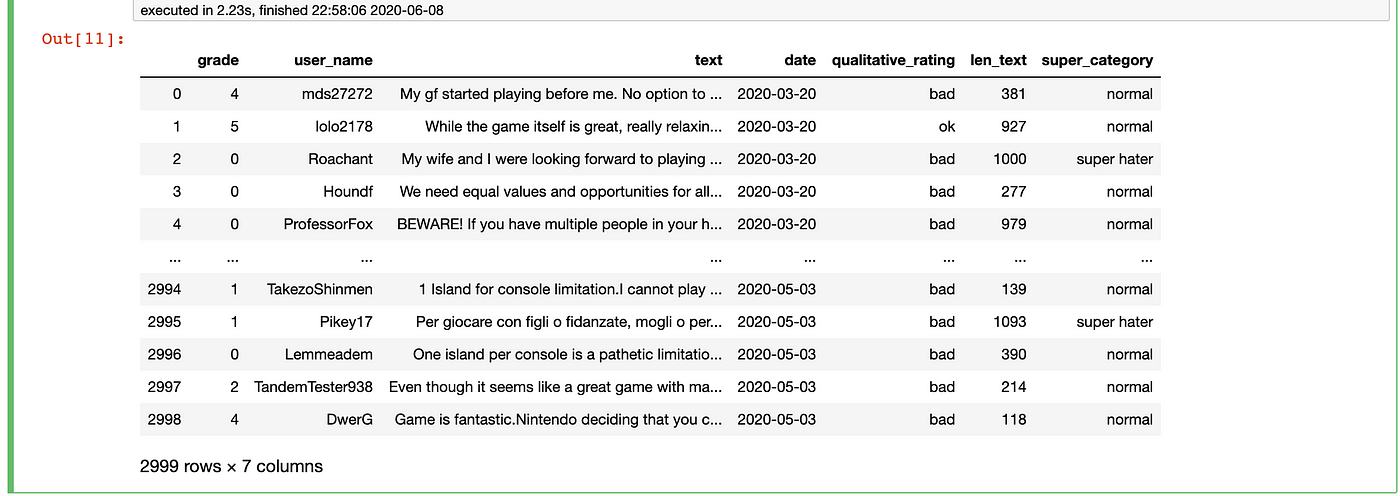
This works, merely permit's cut it in one-half:
# new column based on multiple conditions (new) # create new column
new['super_category'] = 'normal' # ready multiple conditions and assign reviewer category with .loc
new.loc[(new['grade'] == 10) & (new['len_text'] >= 1000), 'super_category'] = 'super fan'
new.loc[(new['class'] <= 1) & (new['len_text'] >= 1000), 'super_category'] = 'super hater'
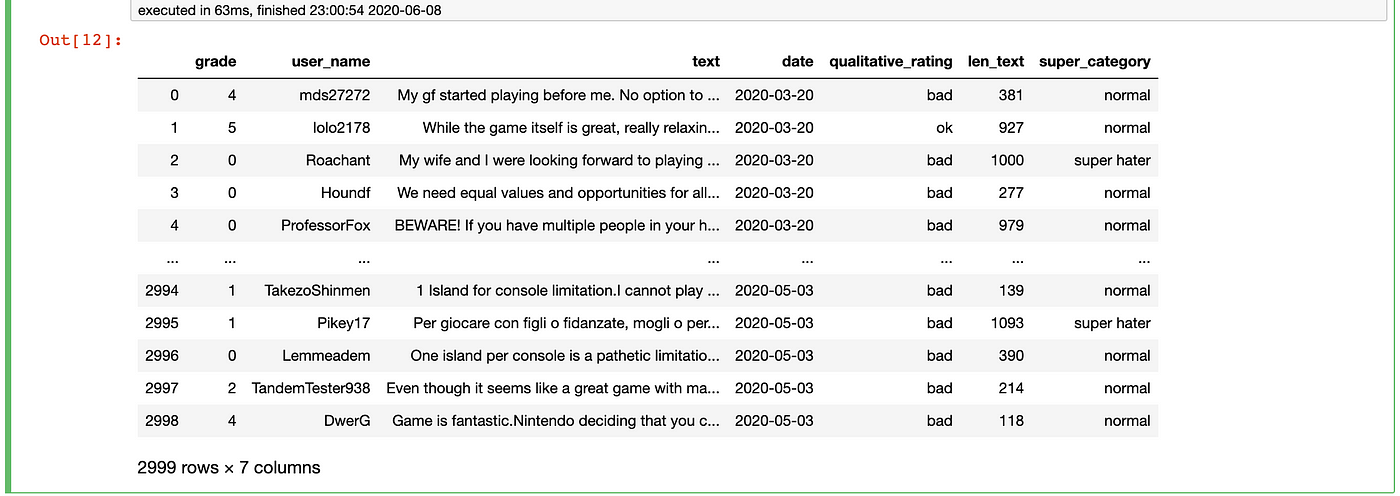
Here, we apply the "&" operator inside our ".loc" part to implement the two atmospheric condition at once. The vectorized solution completed in 63 milliseconds, which again is significantly faster than the loop method, which took 2.23 seconds.
These were some basic operations used to aggrandize the existing data with some of our own custom analysis. Aye, we could have done everything with loops, and you can even encounter that the same structure practical across many different operations. But Pandas comes with a lot of built-in methods specifically for the operations that we oftentimes need to perform.
Going through this helped me retrain my brain away from always going to for loops as a solution to looking for better ways to accomplish all sorts of operations.
I promise it helped you do the same!

Source: https://towardsdatascience.com/you-dont-always-have-to-loop-through-rows-in-pandas-22a970b347ac
Posted by: ballgairciand.blogspot.com
0 Response to "How To Loop Through Dataframe And Change Values Python"
Post a Comment